
NGS Explained - Next Generation Sequencing Step-by-Step
- Dec 12, 2022
- 5 min read
NGS (Next Generation Sequencing) can sequence a whole human genome in a single day, a process that took over 30 years with the Human Genome Project. This animation explains how NGS works step-by-step, including library preparation, cluster generation, sequencing by synthesis, and how billions of DNA strands are sequenced simultaneously. You'll also learn how NGS compares to Sanger sequencing, how sequencing reads are filtered and mapped to a reference genome, and the key applications of NGS in research and medicine. Watch the YouTube video or continue below to find out more.

The Human Genome Project and the First Genome Sequence
The Human Genome Project uncovered all 3.2 billion bases of the human genome. This project started in 1990 and took until 2000 to complete 85% of the first genome. But, in 2022, the gaps got filled, and the sequence became complete. So, in total, sequencing the human genome took 32 years!

NGS and the One Day Genome
Now, with Next Generation Sequencing (or NGS), it takes only a day to sequence a person's entire genome. One day is a dramatic speed increase compared to 32 years! The difference is due to the number of DNA strands sequenced at once. Billions of DNA strands get sequenced simultaneously using NGS. However, only Sanger Sequencing was available for the Human Genome Project. With Sanger Sequencing, only one strand can get sequenced at a time.
The Basic Principle of NGS
However, NGS only works because the Human Genome Project created a human reference DNA sequence. The basic principle behind NGS is that DNA can be cut into small pieces and sequenced. The sequences of these small pieces then get assembled based on the reference genome.
What are the Steps of NGS?
Nucleic Acid Extraction Followed by Library Prep
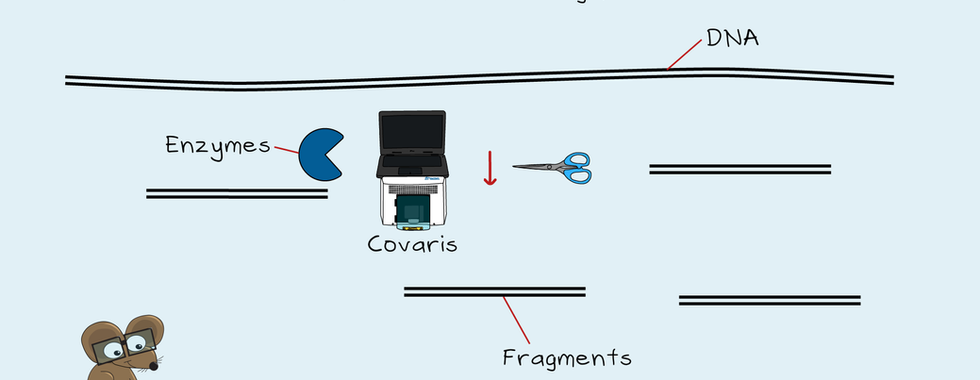
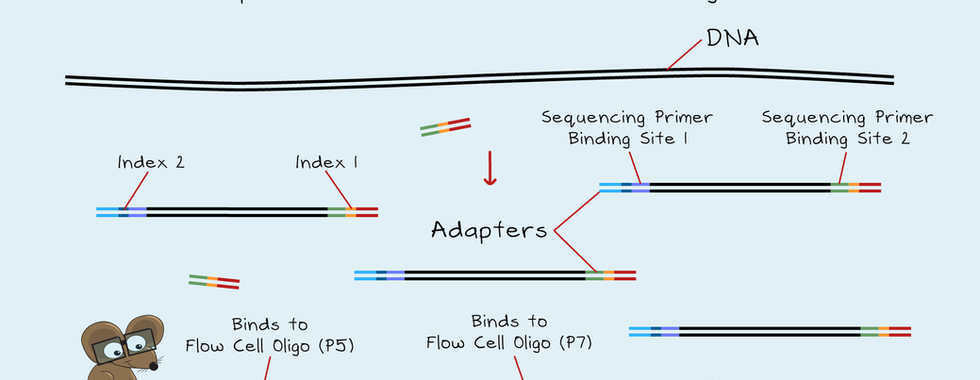
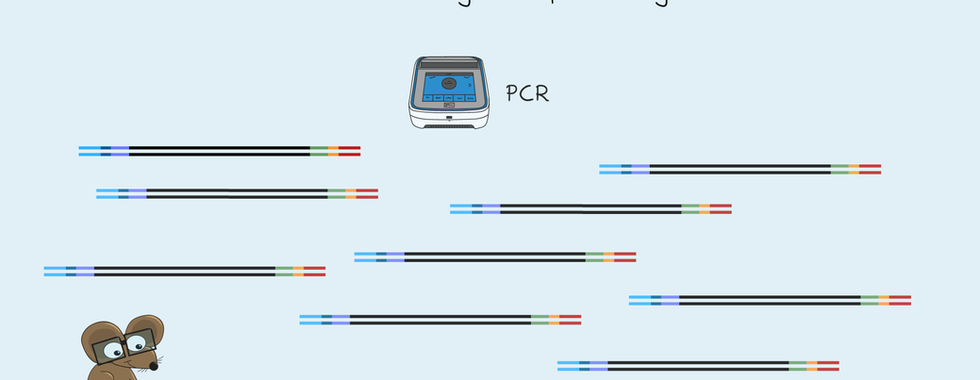
NGS can be used to sequence both DNA and RNA. First, samples get collected, and the DNA or RNA gets purified. Next, the DNA or RNA gets checked to ensure it's pure and undegraded. RNA first needs to be reverse transcribed into DNA before it can get sequenced. A library then gets prepared from the DNA. A library is the collection of short DNA fragments from a long stretch of DNA. Libraries get made by cutting the DNA into short pieces of a specific size. This cutting gets done using high-frequency sound waves or enzymes. Then sequences of DNA called adapters get added to each end of a DNA fragment. These adapters contain the information needed for sequencing. They also include an index to identify the sample. Finally, any non-bound adapters get removed, and the library is complete. Depending on the application, there can be a PCR step to increase the library amount. A successful library will be of the correct size. It will also be of a high enough concentration for sequencing.






The Steps of the SBS Reaction:
Attaching the Library to the Flow Cell
The main sequencing instruments used in NGS are from Illumina. These instruments use a method called sequencing by synthesis. The sequencing occurs on a glass surface of a flow cell. Short pieces of DNA called oligonucleotides are bound to the surface of the flow cell. These oligonucleotides match the adapter sequences of the library. First, the library gets denatured to form single DNA strands. Then this library gets added to the flow cell, which attaches to one of the two oligos. The strand that attaches to the oligo is the forward strand. Next, the reverse strand gets made, and the forward strand gets washed away. The library is now bound to the flow cell.

Cluster generation from the library fragments
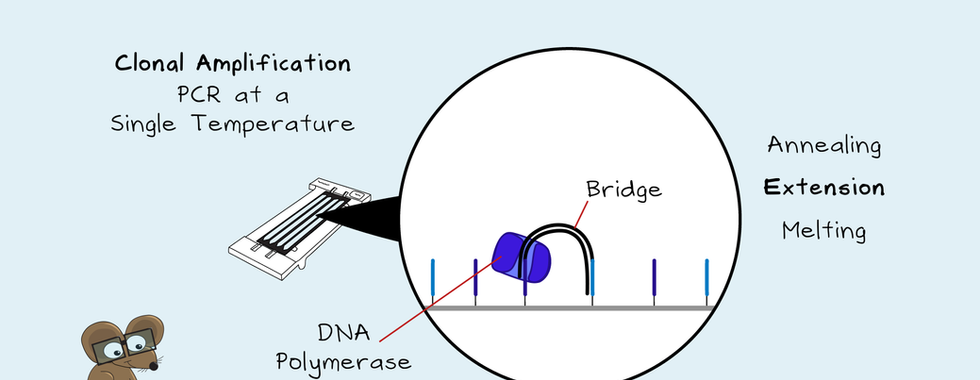
If sequencing started now, the fluorescent signal would be too low for detection. So, each unique library fragment needs to get amplified to form clusters. This Clonal Amplification is by a PCR that happens at a single temperature. Annealing, extension and melting occur by changing the flow cell solution. First, the strands bind to the second oligo on the flow cell to form a bridge. The strands get copied. Then these double-stranded fragments get denatured. This denaturation gets done by adding another solution to the flow cell. This copying and denaturing repeats over and over. Localised clusters get made, and finally, the reverse strands get cut. These strands get washed away, leaving the forward strand ready for sequencing.







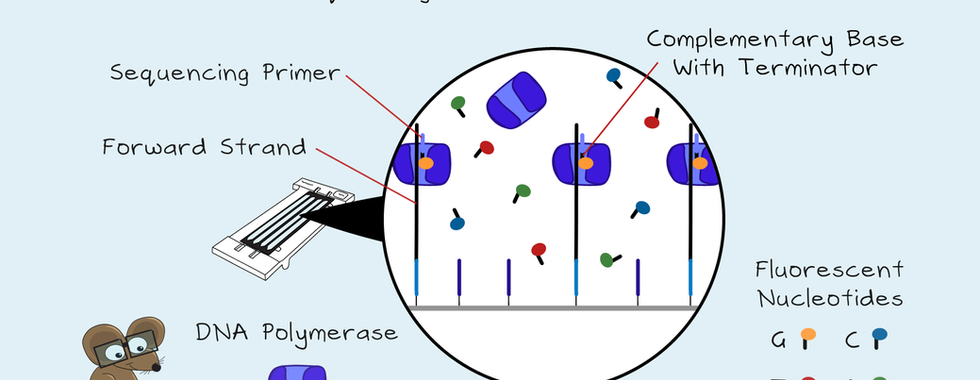
Sequencing of the DNA strands and Indexes
The sequencing primer binds to the forward strands. Next, fluorescent nucleotides G, C, T and A get added to the flow cell along with DNA Polymerase. Each nucleotide has a different colour fluorescent tag and a terminator. So only one nucleotide can get sequenced at a time. First, the complementary base binds to the sequence. Then the camera reads and records the colour of each cluster. Next, a new solution flows in and removes the terminators. The nucleotides and DNA Polymerase flow in again, and another nucleotide gets sequenced. These read cycles continue for the number of reads set on the sequencer. Once complete, these read sequences get washed away. Then the first index gets sequenced, then washed away. If only a single read is needed, the sequencing ends here. But, for paired-end sequencing, the second index is sequenced, as well as the reverse strand of the library. There is no primer for the second index read. Instead, a bridge gets created so that the second oligo acts as the primer. The second index is then sequenced. These two index reads use unique dual indexes. These allow the use of up to 384 samples in the same flow cell. Next, the reverse stands get made, and the forward strands are cut and washed away. The reverse stands are then sequenced.



Aligning and Making Sense of the Reads
Once the sequencing is complete, any bad reads get filtered out. These include the clusters that overlap, lead or lag with sequencing or are of low intensity. The clusters can't overlap on a patterned flow cell, but there can be more than one library fragment per nanowell. These polyclonal wells will also get filtered out. Next, the reads passing the filter get demultiplexed. Demultiplexing uses the attached indexes to identify, and sort reads from each sample. Finally, the reads get mapped to the reference genome. The different reads align to the reference genome, overlapping each other. Paired-end sequencing creates two sequencing reads from the same library fragment. During sequence alignment, the algorithm knows that these reads belong together. Longer stretches of DNA or RNA can get analysed with greater confidence that the alignment is correct.

Read depth is an essential metric in sequencing. Read depth is the number of reads for a nucleotide. Average read depth is the average depth across the region sequenced. For whole genome sequencing, a 30x average read depth is good. A 1500x average read depth is suitable for detecting rare mutation events in cancers. Another essential metric is coverage. The aim is to have no missing areas across the target DNA.

How is NGS Being Used?
NGS gets used in a wide variety of applications. In diagnosing cancer and rare disease, treatment guidance for cancers, and many research areas from ecology to botany to medical science. Both DNA and RNA can be sequenced. It could be the whole genome or transcriptome, just the coding regions (called exomes) of the DNA, or target genes in the DNA or RNA. All types of RNA can be sequenced, including non-coding RNAs, such as microRNAs and long non-coding RNA. In addition, cell-free DNA, single cells, as well as methylation or protein binding sites can also get sequenced.






